Enriching Vulnerabilities with AI: Introducing OpenCVE Enrichment
Since the beginning, OpenCVE has relied on official CVE data to help users track vulnerabilities affecting their products. But what happens when this data becomes incomplete, or even missing altogether?
That’s exactly the challenge we’re tackling with OpenCVE Enrichment, our new AI-powered feature designed to automatically enhance CVEs with relevant information.

How OpenCVE Works
Before diving into what’s new, let’s quickly review how OpenCVE traditionally operates.
The CVE dictionary has been maintained by MITRE since 1999. In 2005, the NVD (National Vulnerability Database) was launched to enrich each CVE with additional structured data such as CVSS scores, CWE categories, and, most importantly for us, CPEs.
CPEs (Common Platform Enumerations) are standardized identifiers that describe which products and versions are affected by a given CVE. For example, the CPE string
cpe:2.3:a:apache:log4j:*:*:*:*:*:*:*:* means that all versions of the log4j product from the apache vendor are affected by that CVE.
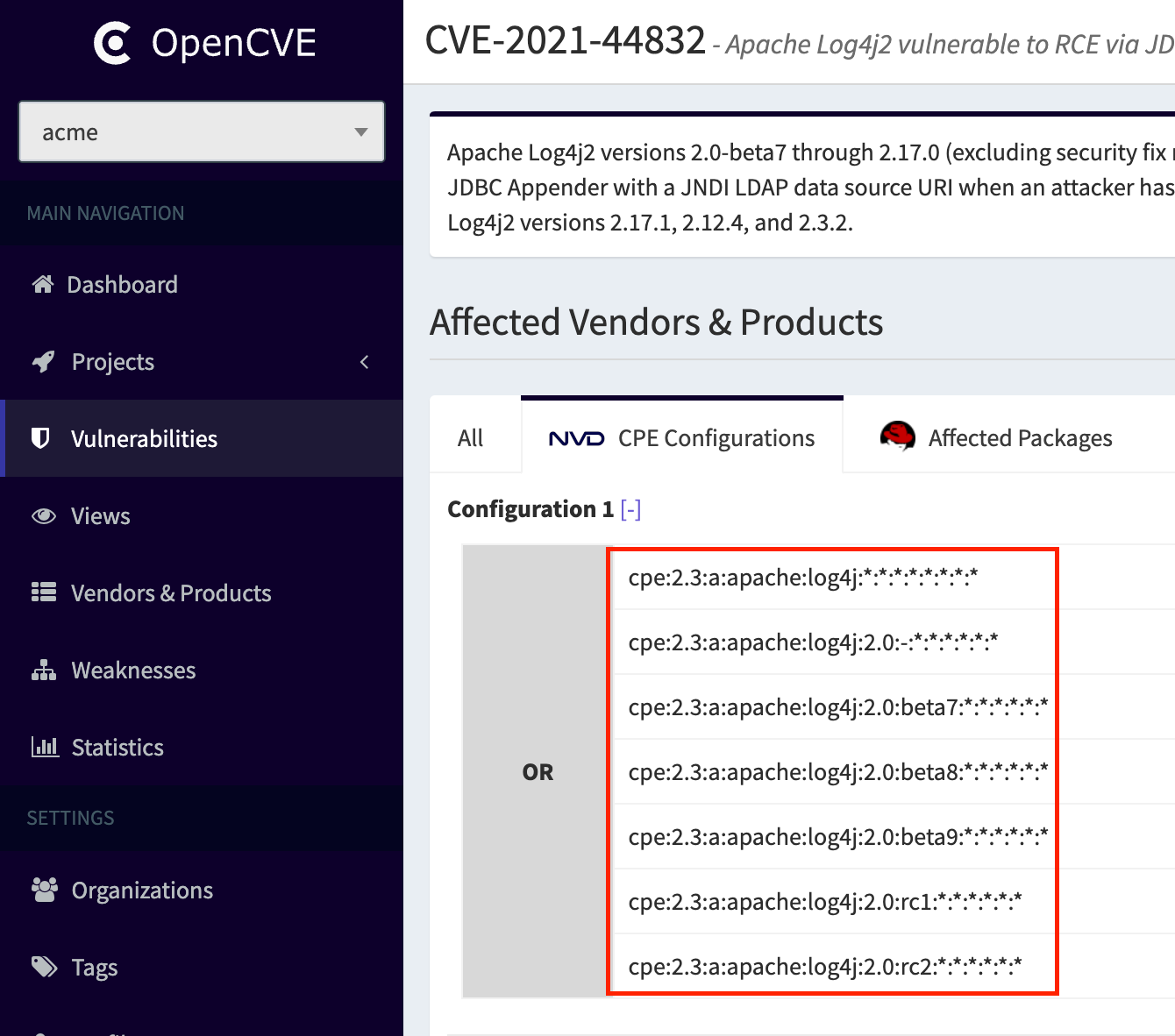
At the core of OpenCVE is the ability to match CPEs to vendors and products. For each CVE, or whenever new CPEs are added, we extract the relevant vendor/product pairs and associate them with the vulnerability.
If a user subscribes to a product like log4j, they’ll get notified as soon as a related CVE is published or updated.

The Problem
Since February 2024, the NVD has faced severe delays and even near-complete halts in CVE enrichment. The causes include funding issues, a growing backlog, and organizational challenges in the U.S. As a result, many recent CVEs lack essential metadata like CVSS, CWE, or CPE entries.
Other organizations have responded to this gap. The CISA launched the Vulnrichment project in May 2024, aiming to provide contextual enrichment of public CVE data (e.g., exploitation status, severity scoring, categorization). This helps improve vulnerability prioritization and relevance.
OpenCVE quickly integrated support for Vulnrichment to benefit from this new layer of enrichment.
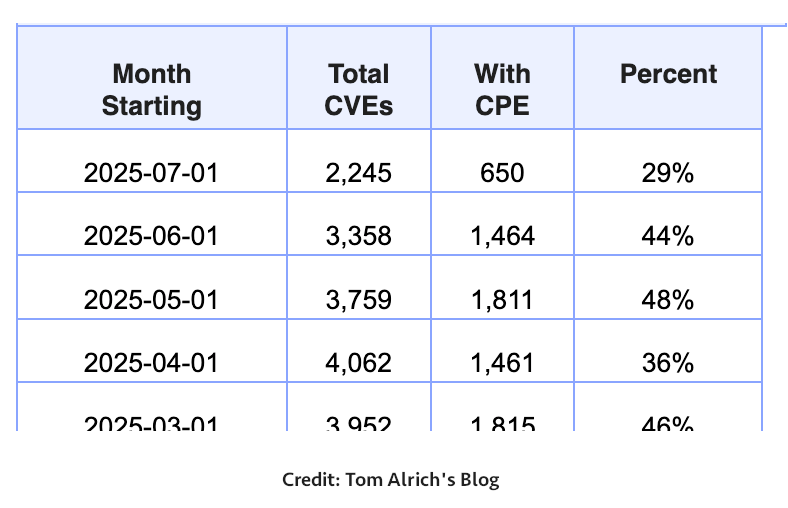
But the reality remains concerning. As highlighted in Tom Alrich’s July 2025 blog post, only 29% of CVEs published in January 2025 had at least one CPE. No CPE means no vendor or product association, and no user alerts.
Our Solution: OpenCVE Enrichment
To address this, we’ve spent the past few months building an AI-driven enrichment system.
Here’s how it works. 👇
Step 1 – Using a LLM to Extract Vendor/Product Data
The first phase involves analyzing the CVE’s content using a Large Language Model. We feed it the CVE title, description, MITRE’s known CNA vendors and products, and known references.
We selected Mistral Magistral Small 1.0 for this task due to its excellent performance, its reasoning capabilities and ease of deployment. We’re using LLAMA.CPP to load the model and expose it via an internal API. We host the model and the LLAMA.CPP stack on our own servers to maintain full control over all the information we use.
For each request, we send both a system prompt and a user prompt. Over time, we’ve refined these prompts to capture domain-specific patterns.
For example:
- Linux Kernel: If the CVE contains “in the Linux kernel” and the CNA lists
linux:linux, we instruct the model to returnlinux:linux_kernelwith high confidence (e.g., 99). - WordPress: If “WordPress” is mentioned, the model must return
wordpress:wordpresswith a confidence score of 99.
We’ll continue improving the prompt to further tailor the results.
In the end, the LLM returns a list of candidate vendor/product pairs, each with a confidence score between 0 and 100.
The results are very encouraging: even with limited information, such as a CVE containing only a description, we’re able to extract the impacted vendors and products.
Step 2 – Matching with Our Internal Database
Next, we attempt to match the LLM’s output with OpenCVE’s internal list of known vendor/product pairs. This is essential: if a user subscribed to product_foobar, we don’t want to miss it because the model returned product-foobar.
To achieve this, we use fuzzy matching techniques with several scoring methods to determine how close the LLM suggestions are to existing entries:
fuzz.ratio: basic Levenshtein distance comparison.fuzz.partial_ratio: useful for substrings.fuzz.token_sort_ratio: compares sorted tokens for order-insensitive matches.fuzz.token_set_ratio: flexible, handles extra/missing tokens well.fuzz.WRatio: a smart hybrid scoring method.
We perform multiple attempts:
extractOne()for the strongest match.extractBests()for the top 5 candidates.
If nothing meets the threshold (85 by default), we fall back to the LLM’s suggestion.
Step 3 – Review and Enrichment
A scheduled task retrieves new CVEs and runs the full enrichment pipeline.
We’ve also developed an interface to manually review and validate the vendor/product matches returned by the LLM and the fuzzy matcher:
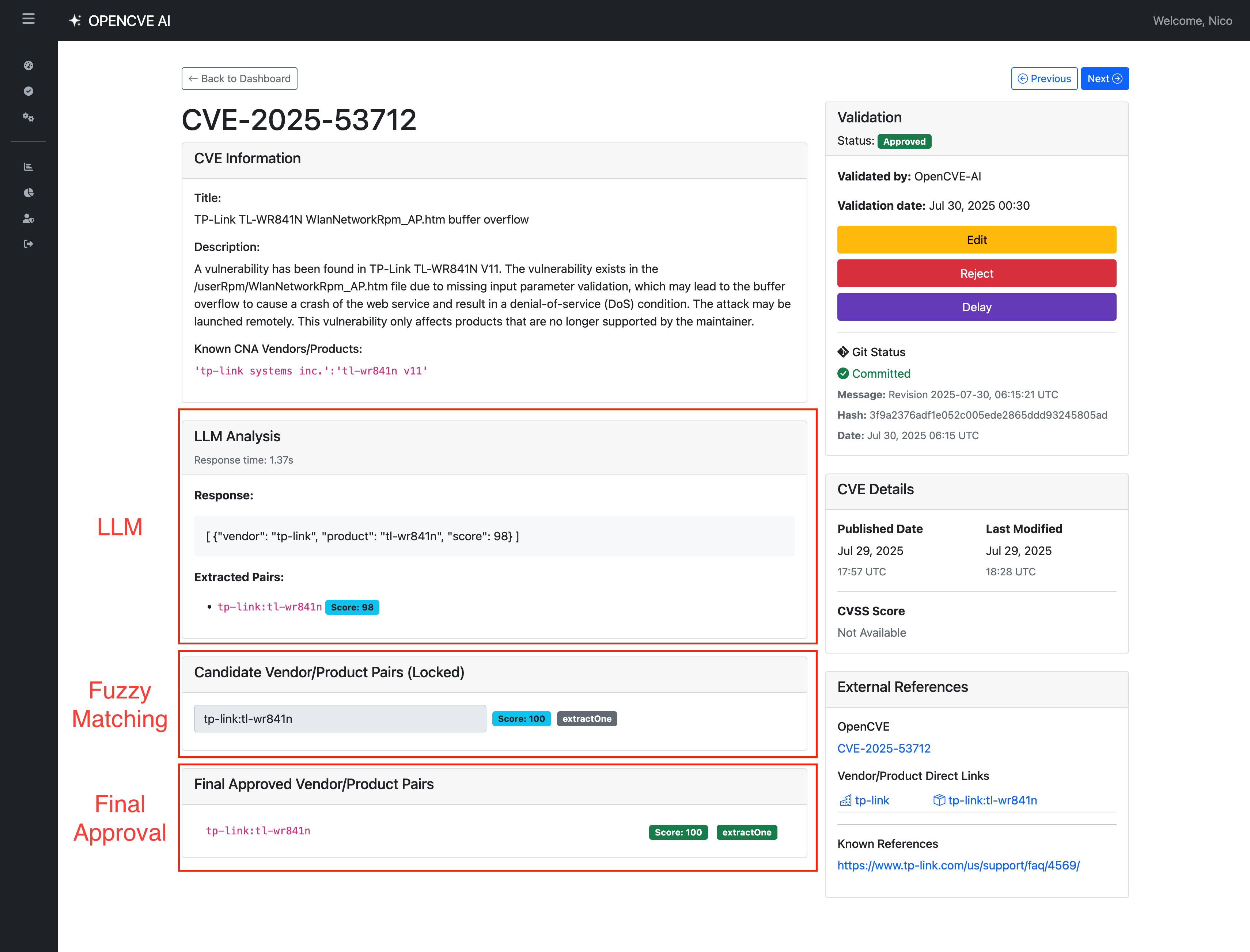
Once validated, the results are published in our public enrichment repository. Today, this review process is manual. But as we gain confidence, we’ll progressively allow auto-committing high-confidence matches (score = 100).
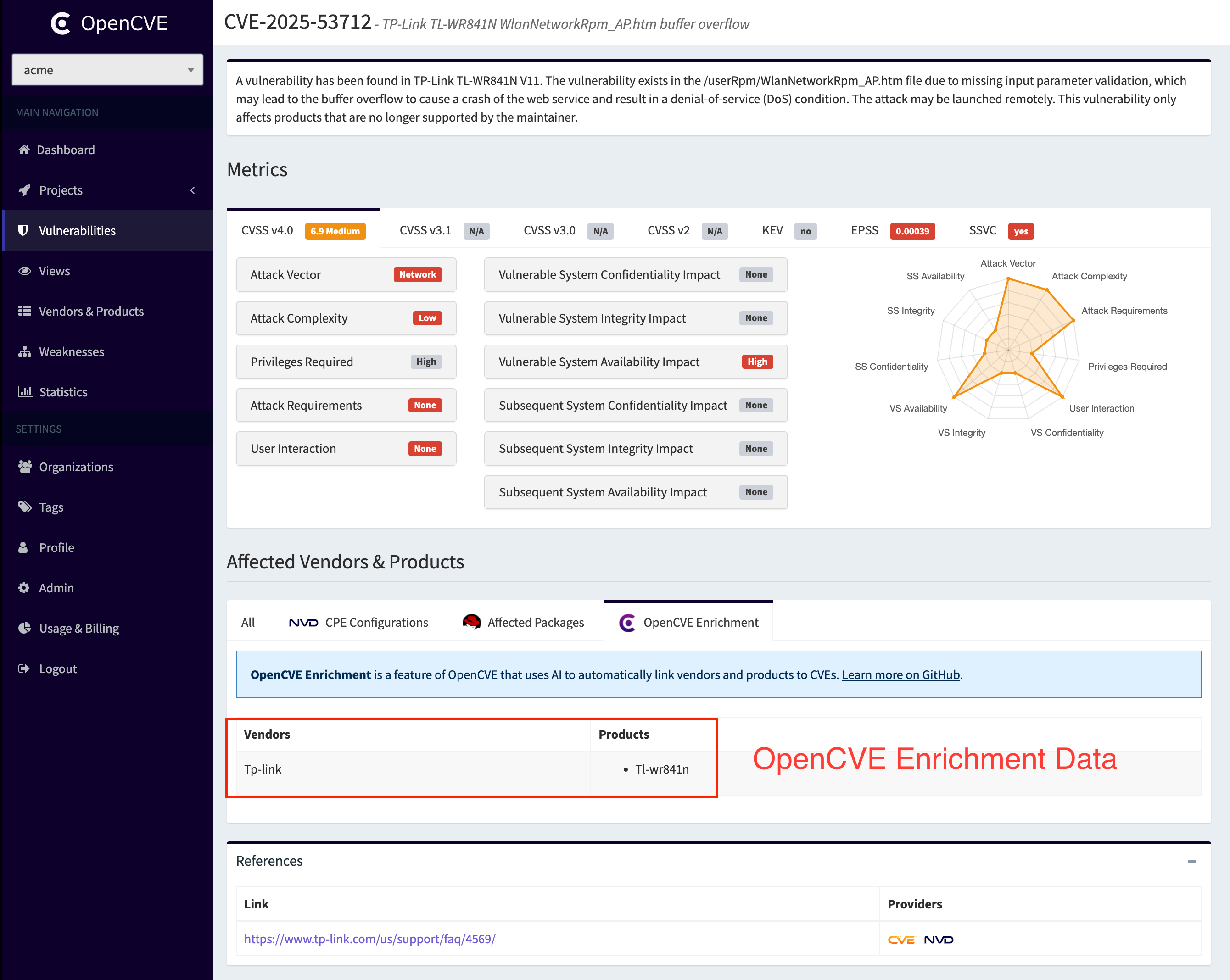
Then the new vendor/product pairs are integrated into our central knowledge base (KB) and the CVE can be linked to the new vendor(s) and product(s):
Statistics
This feature has been live for just two weeks, and we’ve already enriched nearly 30% of all CVEs published in 2025, specifically those that initially had no associated vendors or products.
Our system significantly reduces this blind spot, ensuring that valuable CVE data doesn’t go unlinked or underutilized.
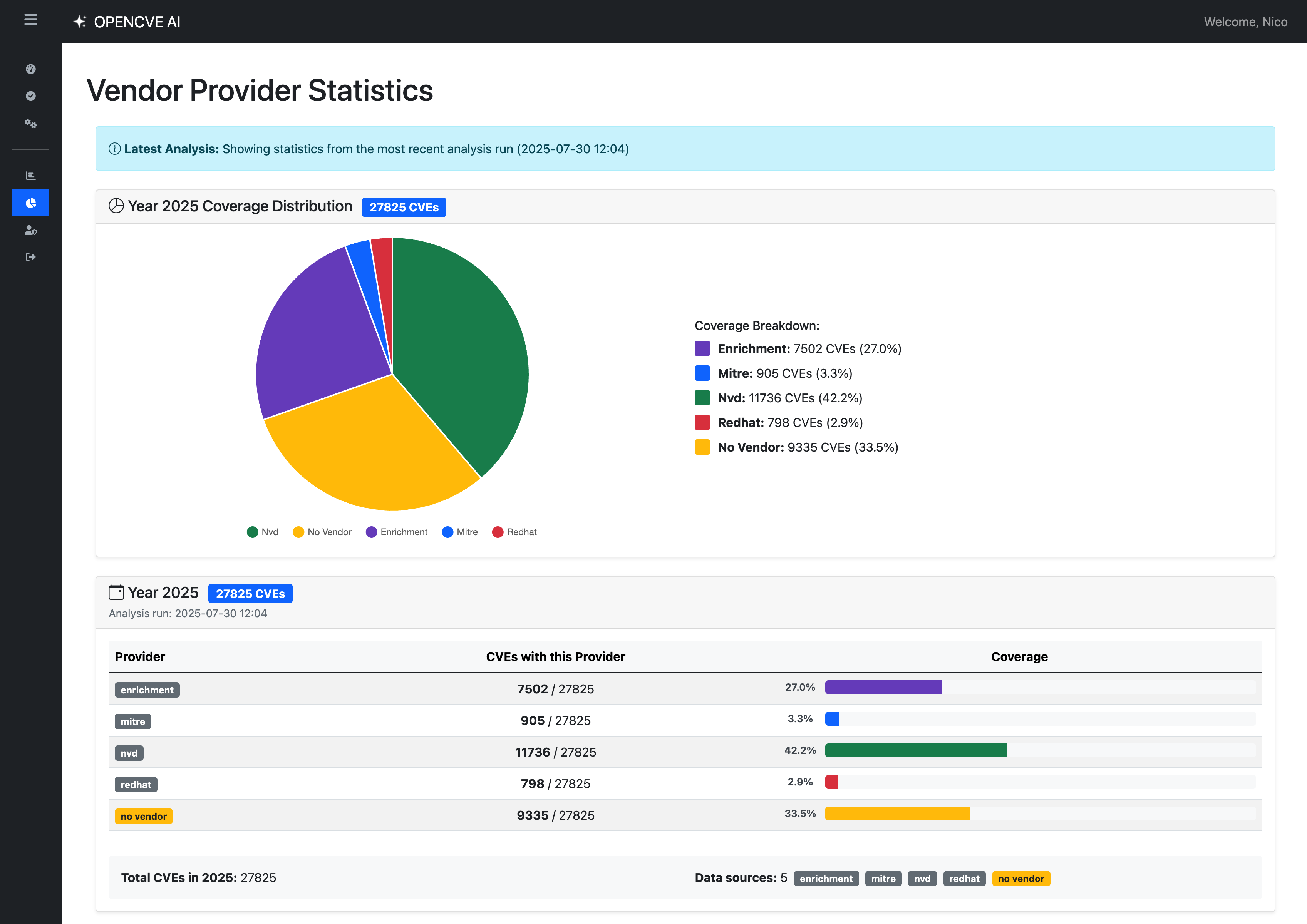
Looking ahead, our goal is to reprocess the entire CVE database, starting with the most recent years, to provide the most comprehensive and reliable coverage possible.
And Next?
This is just the beginning. 🚀
While our current focus is on extracting vendor and product data, our roadmap includes enriching CVEs with:
- Summaries and contextual descriptions
- Risk indicators (e.g., active exploitation)
- CPEs and pURLs
- References and exploit links
- and more…
By combining AI with manual curation and user feedback, OpenCVE Enrichment aims to fill the gaps left by official sources, and empower security teams with better, faster, and more actionable data.
Stay tuned, and if you like what we’re building:
- ⭐️ Star us on GitHub to support the project
- 🧪 Create a free account to explore OpenCVE in action